目录
Part III. Low-Level APIs
通常用Part II的APIs就够了,它通常“more efficient, more stable, and more expressive”,还能省内存。
需要底层APIs的情况:
- 高层无法满足,如准确控制数据的物理位置
- 维护一些RDD写的代码
- 自定义一些共享变量
底层APIs包括两类:RDD和共享变量
入口:SparkSession.SparkContext,是集群和Spark App的联系
Resilient Distributed Datasets (RDDs)
RDDs是1.X的主要API,2.X直接用的比较少。
1.介绍
RDD在物理层面就是一批节点上的一批数据(由关联的partition组成),代码中是底层数据结构,是“an immutable, partitioned collection of records”,每个records就是某一编程语言的object,不像DF,每个record被schema限制。然而,这需要自己造轮子,比如自己定义object(属性,方法,接口等),做更多手动调优(因Spark不了解这个object)。通过Java和Scala使用RDD的消耗不大,主要在于处理raw objects(Spark不懂)。python就耗费大了。
正式定义RDD的主要特征:
- partitionlist:
getpartitions()返回partition对象的数组,数组的index对应下面partitioner中的getPartition - 计算每个partition的函数:
iterator(p, parentIters),p是partition,parentIters是来源RDD的iterator,该函数被action函数调用 - 与其他RDD的依赖list(用于数据恢复):
dependencies()返回a Seq of dependency对象,反映依赖关系 - 可选,KV RDD的partitioner,基于hash或range,可自定义(通常使用RDD的原因):
partitioner()返回partitioner对象[Scala option类],如果RDD非tuple,则返回null - 可选,一个preferred locations list(for HDFS file,尽可能将计算任务分配到其所在的存储位置):
preferredLocations(p)返回p在哪个节点的信息a Seq of strings,
RDD遵循Spark的编程范式,如transformations, lazily, actions。其中action包括:reduce, collect, count, first, take, takeSample, takeOrdered, saveAsTextFile, saveAsSequenceFile, saveAsObjectFile, countByKey, foreach等。大部分写到Hadoop的function只适用于pairRDD或NewHadoopRDD
RDD类似Dataset,互相转化方便(rdd -> df可能需要一点运算)。但Dataset是储存在或利用结构化数据engine的,Spark对它提供更多便利和优化。
RDDs有很多种类,大部分被DF API用于优化physical execution plans。用户一般只会用到泛型RDD或key-value RDD。RDD包裹不同的数据类型决定其所能调用的函数,如果数据类型的信息丢失,相应的函数调用自然会失败。
细节补充:
(1)弹性:内存放不下,自动到磁盘
(2)容错:某节点数据丢失后,自动从其来源节点重新计算 (3)位置感知:上面的依赖list(4)RDD除了上面五个函数实现,还有通用的function。适用于特定类型RDD的函数会定义在特定的function class里,如“PairRDDFunctions, OrderedRDDFunctions, and GroupedRDDFunctions” 通过隐式转使方法可以执行
(5)其他类型RDD,如NewHadoopRDD(通过hdfs创建的rdd),ShuffledRDD(partitioned的rdd)。通过toDebugString可得到rdd类型和他的父rdd列表
(4)RDD依赖:
血统(Lineage):记录RDD的原数据和转换行为,以便恢复丢失数据
(5)不像高层API会自动优化,需要自己安排操作顺序。
2.RDD代码
//创建(不改变来源的类型)//从Dataset[T]到RDD[T]spark.range(100).rdd//从DF[Row]到RDD[Row],所以要转换。也可以toDF转回来spark.range(10).toDF().rdd.map(rowObject => rowObject.getLong(0))//从集合val myCollection = "Spark The Definitive Guide".split(" ")val words = spark.sparkContext.parallelize(myCollection, 2)//也可以当作是把数据分配到集群的方法//从数据源spark.sparkContext.textFile("path")//每个record一行stringspark.sparkContext.wholeTextFiles()//每个record一个file(文件名为第一个对象,文件值为第二个对象?)//其他sequenceFile(Hadoop序列化类型), hadoopRDD, objectFile(针对saveAsObjectFile进行反序列化)//可为RDD取名,并显示在UIwords.setName("myWords")words.name//transformation: distinct,filter, map(MapPartitionsRDD), flatMap, sortwords.randomSplit(Array[Double](0.5, 0.5))//返回RDD数组,第一个参数为比重,第二个为种子//actions: reduce(f:(T, T) => T), count, countApprox, countApproxDistinct,countByValue,countByValueApprox,first,max,min,mean,stats,take, takeOrdered, top(takeOrdered的倒序),takeSamplewords.countApprox(timeoutMilliseconds, confidence)words.countApproxDistinct(0.05)//参数为相对精度,至少大于0.000017,越小越占空间words.countApproxDistinct(p, sp)//p为精度,sp为空间精度,相对精度大概为1.054 / sqrt(2^P)。设置非零的sp>p可以可以减少内存消耗和增加精度parsed.rdd//把df转为rdd,下面仅作演示,用df的groupBy("is_match").count().show更好 .map(_.getAs[Boolean]("is_match"))//将rdd中每个row map为Boolean(根据is_match列) .countByValue()//结果Map(true -> 20931, false -> 5728201),会存到driver的内存,只有当row数量小或distinct的数量小才能用。可用countByValueApprox或者reduceByKey(不会把结果返回到client)words.countByValueApprox(timeoutMilliseconds, confidence)words.takeSample(withReplacement, numberToTake, randomSeed)//Set Operation"""union:拼接intersection:取相同,重复的去掉subtract:去掉rdd1中与rdd2相同的元素"""//Saving Files,只能写到纯文本file。存到一个数据源实际上需要迭代每个partition。words.saveAsTextFile("file:/tmp/bookTitle")//2partition各产生一个文件words.saveAsTextFile("file:/tmp/bookTitleCompressed",classOf[BZip2Codec])words.saveAsObjectFile("/tmp/my/sequenceFilePath")//二进制KV对的flat file,主要Hadoop用?//Caching,a)计算结果需要重复使用,b)同一个rdd上多个action,c)计算每个partition的成本很高时使用(Spark app结束后会被删除)。如果rdd不再使用,可用unpersist清理。//详细cache等级看调优部分words.cache()words.getStroageLevel//下面在action之间加persist后,第二个action调用sorted时就不用再执行sortByKey了val sorted = rddA.sortByKey()val count = sorted.count()val sample: Long = count / 10rddA.persist()sorted.take(sample.toInt)//checkpointing,在spark app结束后仍会保存,因保存在更可靠的文件系统中,但血统会被打断(Spark不知道这RDD是怎么得来的)。另外耗费大,记得先persist后checkpoint。spark.sparkContext.setCheckpointDir("/some/path/for/checkpointing")words.checkpoint()//checkpointing和persisting off_heap可以让由于GC或out-of-memory errors而停止的工作完成//pipe, 即使是空的partition也会被调用words.pipe("wc -l").collect()//得到两个结果(一个partition一个)的Array//mapPartitions, f: (Iterator[T]) ⇒ Iterator[U]words.mapPartitions(part => Iterator[Int](1)).sum()//mapPartitionsWithIndex, 下面方便debugg,打印出每个元素所在partitionwords.mapPartitionsWithIndex((partitionIndex, withinPartIterator) => withinPartIterator.toList.map( value => s"Partition: $partitionIndex => $value").iterator).collect()//foreachPartition, f: (Iterator[T]) ⇒ Unit//glom, 将“每一个partition”数据转化为“一个”Array[T],如RDD[Array[String]]spark.sparkContext.parallelize(Seq("Hello", "World","A"), 2).glom()//两个数组Array(Hello), Array(World, A) 3.KV RDD
有两类functions:PairRDDFunctions(任何(K,V))和OrderedRDDFunctions(K必须为ordering,如numeric 或 strings,其他类型要自定义)
//创建, map或keyBywords.map(word => (word, 1))val keyword = words.keyBy(word => word.toLowerCase.toSeq(0).toString)//mapValues, flatMapValues, keys, valueskeyword.mapValues(word => word.toUpperCase)//Array((s,SPARK), (t,THE),...)keyword.flatMapValues(word => word.toUpperCase)// Array((s,S), (s,P), (s,A)...),返回的结果word.toUpperCase会被当作集合拆开,配上当前的key,原本的KV pair会消失。keyword.lookup("s")//查看key为s的value,没有方法以(K, V)的形式显示//sampleByKey和sampleByKeyExact,区别在于每个key抽取到的数量是否99.99%等于math.ceil(numItems * samplingRate)。下面根据sampleMap中的概率map对words进行抽样val distinctChars = words.flatMap(word => word.toLowerCase).distinct .collect()import scala.util.Randomval sampleMap = distinctChars.map(c => (c, new Random().nextDouble())).toMapwords.map(word => (word.toLowerCase.toSeq(0), word)) .sampleByKey(true, sampleMap, 6L)//6L为种子 .collect()//aggregation,定义聚合方式(下面有更复杂的实现,搜索“自定义aggregation”)val KVcharacters = chars.map(letter => (letter, 1))def maxFunc(left:Int, right:Int) = math.max(left, right)def addFunc(left:Int, right:Int) = left + rightval nums = sc.parallelize(1 to 30, 5)//countByKey,countByKeyApprox(timeout, confidence)结果为map(K -> count)//groupByKey的工作原理是把相同Key放到相同executor,如果数据量大且数据严重倾斜,某个executor会不够内存。KVcharacters.groupByKey().map(row => (row._1, row._2.reduce(addFunc)))//groupByKey结果为Map[Char,Long]//reduceByKey,会先在各个partition上reduce,然后shuffle,再最后reduce//aggregate,要设置累加器,这里用0。第一个func在partition内执行,第二个跨partition。nums.aggregate(0)(maxFunc, addFunc)//最后的聚合是在driver上,所以用下面方法更安全//treeAggregate,一些聚合在executor先完成nums.treeAggregate(0)(maxFunc, addFunc, depth)//aggregateByKey,下面先每个partition的同key相加,然后从所有区中选出各key的最值KVcharacters.aggregateByKey(0)(addFunc, maxFunc).collect()//combineByKey,设置combinerval valToCombiner = (value:Int) => List(value)//刚开始如何生成combinerval mergeValuesFunc = (vals:List[Int], valToAppend:Int) => valToAppend :: vals//值和combinerval mergeCombinerFunc = (vals1:List[Int], vals2:List[Int]) => vals1 ::: vals2//combiner和combinerval outputPartitions = 6KVcharacters .combineByKey( valToCombiner, mergeValuesFunc, mergeCombinerFunc, outputPartitions)//foldByKey,设置一个初始值,该初始值会按照Func的规则,如+,作用到每个value上,然后作用后的value再按照Func的规则按key进行聚合。下面结果和aggregateByKey(0)(addFunc, addFunc)一样KVcharacters.foldByKey(0)(addFunc)//注意,乘法用1//cogroup,Join的基础。下面结果类似RDD[(Char, (Iterable[Double], Iterable[Double], Iterable[Double]))],其中Char为Key,一个Iterable对应一个RDD,Double为RDD的value类型charRDD.cogroup(charRDD2, charRDD3)//比用两次join高效。但注意cogroup是full join。会有和groupByKey同样的问题,同key要存在同一个分块里//join,fullOuterJoin,leftOuterJoin,rightOuterJoin,cartesianKVcharacters.join(keyedChars, outputPartitions)//outputPartitions可选//zip,合并两个RDD,结果类似RDD[(T, T)]。注意这两个RDD要有相同数量的partition和元素words.zip(RDD) KV aggregation的总结
| Function | Purpose | Key restriction | out of memory | Slow when |
|---|---|---|---|---|
groupByKey | 按keys分组,每个key一个iterator。 | 默认HashPartitioner当keys是array时,用自定义分块器。 | 某些key的数据太多时。 | 如果没有设定partitioner,会shuffle。distinct的keys越多,或者各keys的数据分布越不均匀,消耗越大。 |
combineByKey | 同上,但结果可以是各种数据类型。要设置combiner的产生方式 | Same as above. | 看怎么聚合及聚合结果。可能同上,或者结果的GC太多 | 同上,但如果是聚合(看表下说明)运算,会快点。 |
aggregateByKey | 同上,但用的是初始累加器 | 同上。 | 同上,但可通过合理设定accumulator来减少GC | 同上,但更快,因为先在各分块执行一次再跨分块执行。 |
reduceByKey | 结果为输入类型。 | See above. | 一般没问题。且没有累加器的产生(少GC) | 同上。 |
foldByKey | 搜索KV RDD代码的说明。 | See above. | See above. | 同上。 |
实际上,所有都是建立在combineByKey的基础上。上面聚合指SeqOp和combOp都是产生一个空间更小的结果。
Mapping and Partitioning Functions of PairRDD
| Function | Purpose | out of memory | Slow when | Output partitioner |
|---|---|---|---|---|
mapValues | 只对值操作 | 取决于map的过程和结果 | map过程复杂或者map后的record比原来更占空间 | 能保存partitioner |
flatMapValues | f: (V) ⇒ TraversableOnce[U] | 同上。 | 同上 | 同上 |
keys | 返回keys(含重复) | Almost never | Essentially free | 同上 |
values | 返回values | Almost never | Essentially free | 不保留 |
sampleByKey | 搜索 sampleByKey | Almost never, 除非map很大(map要被广播) | 没有shuffle | 保留 |
partitionBy | 搜索自定义partition | 取决于什么partitioner | 当每个key有很多值时 | 看设定的partitioner |
OrderedRDD Operations
| Function | Key restriction | Runs out of memory when | Slow when | Output partitioner |
|---|---|---|---|---|
sortByKey下面函数和range partition的结合 | 支持tuple2的key | keys分布不均(相同key的位置和某key数量太多) | 多重复key时。数据倾向会导致后期操作慢。 | Range partitioner.默认分块数和原RDD一样 |
| repartition-And-Sort-Within-Partitions | Key 为ordering | 取决于partitoner | 某key数量太多时慢,而且还要排序。但比partitionBy和mapPartitions 的组合快 | 看设定的partitioner |
filterByRange选择key落在指定范围的records进行filter | See above. | Almost never. | 通过range partitioning的rdd(如sortByKey后)用这方法比较高效,否则跟普通filter一样 | 保留partitioner |
4.RDD Join
三种情况:shuffle, one or both have known partitioners, colocated
三个建议:
join前filter或reduce是个好习惯
如果RDD有重复的keys,最好先用distinct或combineByKey来减少key空间,或者用cogroup来处理重复keys。
如果某key不同时存在于两个RDD,用outerjoin防止数据丢失,之后用filter
针对建议的代码:
//有score(id, score)和student(id, name)的rdd。如果制作一个(id,name,score)的表,且score只要最高分,先用下面的代码去掉多余的score后再joinval bestScore = scores.reduceByKey((x,y) => if (x > y) x else y)bestScore.join(student)//join后再filter时注意格式变化[(key,(v1,v2))]joinedRDD.reduceByKey((x,y) => if (x._1 > y._1) x else y)//have known partition来避免shuffle//上面出现在join前的reduceByKey或aggregateByKey会有shuffle,可以执行前加上下面代码,防止shuffle。在reduceByKey的第一个arg加上scoresDataPartitioner即可val scoresDataPartitioner = scores.partitioner match { case (Some(p)) => p case (None) => new HashPartitioner(scores.partitions.length)}//广播(和DF一样,但要手动设置。实际上就是广播一个map)import scala.collection.Mapimport scala.reflect.ClassTagdef manualBroadCastHashJoin[K : Ordering : ClassTag, V1 : ClassTag, V2 : ClassTag](bigRDD : RDD[(K, V1)], smallRDD : RDD[(K, V2)])= { val smallRDDMapLocal: Map[K, V2] = smallRDD.collectAsMap()//注意smallRDD不能有相同key不同value,否则只会取一个key-value bigRDD.sparkContext.broadcast(smallRDDMapLocal) bigRDD.mapPartitions(iter => { iter.flatMap{ case (k,v1) => smallRDDMapLocal.get(k) match {//下面None和Some都是Option的子类 case None => Seq.empty[(K, (V1, V2))]//没有批对的key就去掉,也可设默认值Seq((k, (v1, 0))) case Some(v2) => Seq((k, (v1, v2))) } } }, preservesPartitioning = true)}//上面smallRDDMapLocal.get可改为getOrElsecase (k,v1) => { val v2 = smallRDDMapLocal.getOrElse(k, 0) Seq((k, (v1, v2)))}//部分广播,利用countByKeyApprox或者countByKey+sort后取前k个key Advanced RDDs
1.partition
了解partition
默认从storage(checkpointing产生的除外)加载的数据是没有partitioner的,会根据数据和分块的大小来分配数据到partitions。
//下面代码结果为(1,None),(1,None),(2,None)...均匀分布在8个partitions(即有两个空了)数据刚开始sc.parallelize时是没有partitioner,所以均匀分布val rdd = sc.parallelize(for { x <- 1 to 3 y <- 1 to 2} yield (x, None), 8)//计算每个分块的records数量rdd.mapPartitions(iter => Iterator(iter.length)).collect()//显示每个分块各保存了什么数据df.rdd.mapPartitions(iter => Iterator(iter.map(_.getString(0)).toSet)).collect()//有了partitioner之后,就会按key来shuffle。如下面重分块为2份,结果是2在一个分块,1,3在另一个分块。Scala RDD的分区根据k.hashCode % numOfPar;DataSets用MurmurHash 3函数,pyspark用其他。import org.apache.spark.HashPartitionerval rddTwoP = rdd.partitionBy(new HashPartitioner(2))rddTwoP.mapPartitions(iter => Iterator(iter.map(_._1).toSet)).collect()//结果Array(Set(2), Set(1, 3)) 控制partition
重分块后记得persist
//合并partition,较少partition来减少shufflecoalesce(numPartitions)//重partition,伴随shuffle,但增加partitions有时可提高并行效率,使用hash partitioningrepartition(numPartitions)//重partition并区内排序。用于排序的key可以另外设定repartitionAndSortWithinPartitions(partitioner)
自定义partition
其定义partition的目的是让数据较为均匀地分布到各partition。partition需要对数据的业务情况有很好的了解,如果仅仅是为了一个值或一组cols值,这是没必要的。本书建议完成partition后回到结构化API。
Spark有两个内置Partitioners,"HashPartitioner for discrete values and a RangePartitioner for continuous"。结构化APIs就是用他们进行partition的。另外,pairRDD操作用的是hash。
具体来说,range partitioning需要分块数和rdd参数,其中rdd为tuple且key为ordering。它先需要sort,然后通过sample来确定各partition的分配范围,最后才正式分布。key值的不平衡会影响sample的准确性,这样的partitioning可能使后面的计算更低效,甚至out-of-memory。总体来说,比hash消耗大。
//下面利用HashPartitionerpartition,arg默认值为SparkConf中设置的spark.default.parallelism,如果该值没有设置,就是该rdd血统的存在过的最大值val keyedRDD = rdd.keyBy(row => row(6).asInstanceOf[Int].toDouble)keyedRDD.partitionBy(new HashPartitioner(10)).take(10)//自定义partition。还可以实现equals方法(hashcode也要实现),当partitioner相同时,不再shuffle。hash的是当numPartitions相等时为true。class DomainPartitioner extends Partitioner { def numPartitions = 3 def getPartition(key: Any): Int = {//返回的数值为0~numPartitions-1 val customerId = key.asInstanceOf[Double].toInt //Double为key的类型 if (customerId == 17850.0 || customerId == 12583.0) { //特定为这两个ID分一个区 return 0 } else { return new java.util.Random().nextInt(2) + 1 } }}//下面的代码显示每个partition所得ID的数量keyedRDD.partitionBy(new DomainPartitioner).map(_._1).glom().map(_.toSet.toSeq.length) 部分narrow transformation可以保持partitioner,如mapValues。用map、flatMap等,即便不改变key,还是会失去partitioner。另外,下面mapPartitions设置也可保持partitioner
prdd.mapPartitions(iter => Iterator(iter.map(v => (v._1, v._2)).toArray), preservesPartitioning = true).partitioner
Co-Located and Co-Partitioned RDDs
Co-Located指分布在内存的位置相同。如果两个rdd被相同的job分布到内存,且拥有相同partitioner,就会是co-located,能方便CoGroupedRDD函数,如cogroup和join等。
Co-Partitioned指拥有相同partitioner的rdd。
//下面count执行后,rddA和rddB会是Co-Located。如果把rddA和rddB的注释去掉,则是Co-Partitionedval rddA = a.partitionBy(partitioner)rddA.cache()val rddB = b.partitionBy(partitioner)rddB.cache()val rddC = a.cogroup(b)//rddA.count()//rddB.count()rddC.count()
2.自定义Aggregation函数
aggregateByKey需要三个参数:rdd.aggregateByKey( accumulators )( sequence func, combine op )
下面代码的需求:上面的rdd,其key是教师名,value是report cards。现想知道所有report cards的统计结果,具体是所有成绩单的longestWord,happyMentions(“happy”出现的次数),totalWords.toDouble/numberReportCards平均字数。为此先建立一个累加器MetricsCalculatorReuseObjects(其实累加器可以用array实现,方法通过object类定义,这样更省空间)。
//tag::calculator[]class MetricsCalculatorReuseObjects( var totalWords : Int, var longestWord: Int, var happyMentions : Int, var numberReportCards: Int) extends Serializable { //表示把value添加到累加器的函数 def sequenceOp(reportCardContent : String) : this.type = {//返回还是原来的累加器 val words = reportCardContent.split(" ") totalWords += words.length longestWord = Math.max(longestWord, words.map( w => w.length).max) happyMentions += words.count(w => w.toLowerCase.equals("happy")) numberReportCards +=1 this } //表示各累加器加总的函数 def compOp(other : MetricsCalculatorReuseObjects) : this.type = { totalWords += other.totalWords longestWord = Math.max(this.longestWord, other.longestWord) happyMentions += other.happyMentions numberReportCards += other.numberReportCards this } //从最终累加器中导出结果的函数 def toReportCardMetrics = ReportCardMetrics( longestWord, happyMentions, totalWords.toDouble/numberReportCards)}//end::calculator[]//存放结果的case classcase class ReportCardMetrics( longestWord : Int, happyMentions : Int, averageWords : Double)//实现上述需求的函数def calculateReportCardStatisticsReuseObjects(rdd : RDD[(String, String)] ): RDD[(String, ReportCardMetrics)] ={ rdd.aggregateByKey(new MetricsCalculatorReuseObjects(totalWords = 0, longestWord = 0, happyMentions = 0, numberReportCards = 0))( seqOp = (reportCardMetrics, reportCardText) => reportCardMetrics.sequenceOp(reportCardText), combOp = (x, y) => x.compOp(y)) .mapValues(_.toReportCardMetrics)}//上面代码也可写成这样 val accumulator = new MetricsCalculatorReuseObjects(totalWords = 0, longestWord = 0, happyMentions = 0, numberReportCards = 0) def seqOp = (reportCardMetrics : MetricsCalculatorReuseObjects, reportCardText:String) => reportCardMetrics.sequenceOp(reportCardText) def combOp = (x : MetricsCalculatorReuseObjects, y : MetricsCalculatorReuseObjects) => x.compOp(y) rdd.aggregateByKey(accumulator)(seqOp, combOp).mapValues(_.toReportCardMetrics) 零散的优化建议
1.重用已存在的objects。如“自定义Aggregation函数”中seqOp和combOp运用this.type方式,而非new
2.使用primitive types比自定义类和tuple更有效率。比如用array比tuple省事,再如“自定义Aggregation函数”中,用array来实现MetricsCalculatorReuseObjects。
3.减少遍历次数(下面实现也有缺陷,看注释)。如修改上面的sequenceOp:先创建一个单例函数,该函数输入Seq[String],即content.split后的内容,通过toIterator和while loop计算出longestWord和happyMentions。这样避免使用Math.max和words.count对数据进行两次遍历。
object CollectionRoutines{ def findWordMetrics[T <:Seq[String]](collection : T ): (Int, Int)={ val iterator = collection.toIterator//.toIterator需要把collection变为Traversable对象后投影为Iterator,所以创建了两个object var mentionsOfHappy = 0 var longestWordSoFar = 0 while(iterator.hasNext){ val n = iterator.next() if(n.toLowerCase == "happy"){ mentionsOfHappy +=1 } val length = n.length if(length> longestWordSoFar) { longestWordSoFar = length } } (longestWordSoFar, mentionsOfHappy)} 4.减少类型转换。如上面sequenceOp中的.map,它是一个隐式转换;再如上面val iterator = collection.toIterator中,.toIterator需要把collection变为Traversable对象。
3.iterator-to-iterator transformation
定义:f: (Iterator[T]) ⇒ Iterator[U],但没有把把原iterator变为collection或者使用“action”(消耗iterator的操作,如size)来建立新的collection。
这种转换的好处是允许Spark选择性地将溢出的数据写到磁盘。换句话说,因为迭代器里每一个元素相当于一个partition,这样处理整份数据时,可逐个partition,暂时用不到的可以写到磁盘。另外,针对iterator的方法还能较少中间数据结果的产生。
不能对iterator调用sort,要转换为array后才能调用。
//下面用了flatMap,每次的结果返回的都是迭代器。这样如果flatMap结果太大,Spark可以把溢出数据写到磁盘。例子背景看6.KV排序例子pairsWithRanksInThisPart.flatMap{ case (((value, colIndex), count)) => val total = runningTotals(colIndex) val ranksPresent: List[Long] = columnsRelativeIndex(colIndex) .filter(index => (index <= count + total) && (index > total)) val nextElems: Iterator[(Int, Double)] = ranksPresent.map(r => (colIndex, value)).toIterator runningTotals.update(colIndex, total + count) nextElems} 4.KV排序例子
详细查看《high performance spark》github上的代码。
需求:一个df,一列id,其他为该id的属性列(至少两列,一列不需并行,用loop)。编写一个函数,使得输入该df和一个List[Long](要查看的名次),产出Map[Int, Iterable[Double]],Int为属性的列index, Iterable[Double]为List包含该名次对应的数值。
//V1:groupByKey,阅读理解def findRankStatistics( dataFrame: DataFrame, ranks: List[Long]): Map[Int, Iterable[Double]] = { require(ranks.forall(_ > 0)) val pairRDD: RDD[(Int, Double)] = mapToKeyValuePairs(dataFrame)//函数定义在下面 val groupColumns: RDD[(Int, Iterable[Double])] = pairRDD.groupByKey() groupColumns.mapValues(iter => { val sortedIter = iter.toArray.sorted sortedIter.toIterable.zipWithIndex.flatMap({ case (colValue, index) => if (ranks.contains(index + 1)) { Iterator(colValue) } else { Iterator.empty } }) }).collectAsMap()}def mapToKeyValuePairs(dataFrame: DataFrame): RDD[(Int, Double)] = { val rowLength = dataFrame.schema.length dataFrame.rdd.flatMap( row => Range(0, rowLength).map(i => (i, row.getDouble(i))) )} 上面的方法虽然用到了collectAsMap(有out-of-memory可能),但是由于结果的大小是可预料的,Map-key数量为columns数,Map-value为、输入参数list中的名次数量,所以问题不大。问题是当groupByKey遇上数据倾斜。如果是groupByKey后聚合的,直接用aggregateByKey or reduceByKey。
下面Version2排序实现了:同key同partition,在同一partition的key按第一个key来排序(最后变倒序了...),然后同key的按value的第一个值排序,并把value合并。优势在于运用了repartitionAndSortWithinPartitions,而不是上面的groupByKey然后sorted。然而这种操作需要保证一个executor能够容纳hashcode相同的key的record。
//自定义partitioner,由于key是tuple,但只想根据tuple的第一个元素来分块class PrimaryKeyPartitioner[K, S](partitions: Int) extends Partitioner { val delegatePartitioner = new HashPartitioner(partitions) override def numPartitions = delegatePartitioner.numPartitions override def getPartition(key: Any): Int = { val k = key.asInstanceOf[(K, S)] delegatePartitioner.getPartition(k._1) }}def sortByTwoKeys[K : Ordering : ClassTag, S : Ordering : ClassTag, V : ClassTag]( pairRDD : RDD[((K, S), V)], partitions : Int ) = { val colValuePartitioner = new PrimaryKeyPartitioner[K, S](partitions) //隐式,改变repartitionAndSortWithinPartitions的排序方式 implicit val ordering: Ordering[(K, S)] = Ordering.Tuple2 val sortedWithinParts = pairRDD.repartitionAndSortWithinPartitions( colValuePartitioner) sortedWithinParts}def groupByKeyAndSortBySecondaryKey[K : Ordering : ClassTag, S : Ordering : ClassTag, V : ClassTag] (pairRDD : RDD[((K, S), V)], partitions : Int): RDD[(K, List[(S, V)])] = { val colValuePartitioner = new PrimaryKeyPartitioner[Double, Int](partitions) //隐式,改变repartitionAndSortWithinPartitions的排序方式。如果key是case class,看下面的补充说明。 implicit val ordering: Ordering[(K, S)] = Ordering.Tuple2 val sortedWithinParts = pairRDD.repartitionAndSortWithinPartitions(colValuePartitioner) sortedWithinParts.mapPartitions( iter => groupSorted[K, S, V](iter) )}//将相同key的value和为一个listdef groupSorted[K,S,V]( it: Iterator[((K, S), V)]): Iterator[(K, List[(S, V)])] = { val res = List[(K, ArrayBuffer[(S, V)])]() it.foldLeft(res)((list, next) => list match { case Nil => //匹配空的List val ((firstKey, secondKey), value) = next List((firstKey, ArrayBuffer((secondKey, value)))) case head :: rest => //匹配List的第一个值和剩下的值 val (curKey, valueBuf) = head val ((firstKey, secondKey), value) = next if (!firstKey.equals(curKey) ) { (firstKey, ArrayBuffer((secondKey, value))) :: list } else { valueBuf.append((secondKey, value)) list//此时list的valueBuf已经改变 } }).map { case (key, buf) => (key, buf.toList) }.iterator}//注意,下面排序不能保证secondary sortindexValuePairs.sortByKey.map(_.swap()).sortByKey 如果Key是某个case class,如下面的PandaKey,则用下面方法自定义排序。这样后面引用到sortByKey方法的方法,如repartitionAndSortWithinPartitions, sortBeyKey都会按照这个方法排序
implicit def orderByLocationAndName[A <: PandaKey]: Ordering[A] = { Ordering.by(pandaKey => (pandaKey.city, pandaKey.zip, pandaKey.name))}//PandaKey有4个变量,这里只用其中三个排序
Version3:将值作为key,假设value很多样的情况下,sortByKey就不会像以colIndex作为key时会因为某个col值太多而out-of-memory。
def findRankStatistics(dataFrame: DataFrame, targetRanks: List[Long]): Map[Int, Iterable[Double]] = { //getValueColumnPairs将df变为rdd,并把每个Row(x,y,z)变为(x,0),(y,1),(z,2),后面表示colIndex val valueColumnPairs: RDD[(Double, Int)] = getValueColumnPairs(dataFrame) //排序并persist val sortedValueColumnPairs = valueColumnPairs.sortByKey() sortedValueColumnPairs.persist(StorageLevel.MEMORY_AND_DISK) val numOfColumns = dataFrame.schema.length /** * getColumnsFreqPerPartition将 * P1: (1.5, 0) (1.25, 1) (2.0, 2) (5.25, 0) * P2: (7.5, 1) (9.5, 2) * 变为 * [(0, [2, 1, 1]), (1, [0, 1, 1])] * 第一个值表示PIndex,第二个值是各colIndex出现的频率 */ val partitionColumnsFreq = getColumnsFreqPerPartition(sortedValueColumnPairs, numOfColumns) /** * getRanksLocationsWithinEachPart利用上面的频率List找出所查询的targetRanks的在各P的位置,如 * targetRanks: 5 * partitionColumnsFreq: [(0, [2, 3]), (1, [4, 1]), (2, [5, 2])] * numOfColumns: 2 * 结果为: * [(0, []), (1, [(0, 3)]), (2, [(1, 1)])] * 第一个值表示PIndex,第二个值是一个List[Tuple2],每个tuple表示一个target的位置,如(0,3)表示第一列(0)的targetranks位置在该P的第3个(0)出现的位置上。 */ val ranksLocations = getRanksLocationsWithinEachPart( targetRanks, partitionColumnsFreq, numOfColumns) //根据上面结果取值,结果为RDD(column index, value) val targetRanksValues = findTargetRanksIteratively( sortedValueColumnPairs, ranksLocations) targetRanksValues.groupByKey().collectAsMap()} Version4:用value排序时,有可能某些value的值很多,比如0。这种情况下,可以对DF作另外一种转换。其他思路与V3一样。
/** * 代码将 * 1.5, 1.25, 2.0 * 1.5, 2.5, 2.0 * 变为 * ((1.5, 0), 2) ((1.25, 1), 1) ((2.5, 1), 1) ((2.0, 2), 2) * 每个value-用统计的方式表示 */def getAggregatedValueColumnPairs(dataFrame: DataFrame): RDD[((Double, Int), Long)] = { val aggregatedValueColumnRDD = dataFrame.rdd.mapPartitions(rows => { val valueColumnMap = new mutable.HashMap[(Double, Int), Long]() rows.foreach(row => { row.toSeq.zipWithIndex.foreach{ case (value, columnIndex) => val key = (value.toString.toDouble, columnIndex) val count = valueColumnMap.getOrElseUpdate(key, 0) valueColumnMap.update(key, count + 1) } }) valueColumnMap.toIterator }) aggregatedValueColumnRDD} 排序总评:V1的groupByKey和sort可以用V2的repartitionAndSortWithinPartitions来提升效率。V3换了一种思路,不用col作为key,而用value,这能够防止某个col的值过多。V4是当V3有过多重复值时才使用的改进版,用了一个"map-side reduction",即用统计的方式表示KV后才排序。
V1方案最简单,但效果最差。不同方案的选择要考虑 a)原始数据的records数量 b)列数(分组数) c)每列重复值的占比。V2适合大多数情况,只要每个col的值不算太多。如果多但重复值不多(重复值少于“值”数),就V3,重复多就V4(unique值太多时,hash map有out-of-memory风险)。
Distributed Shared Variables
//利用mapPartitions,foreachPartition也算共享吧rdd.mapPartitions{itr => // Only create once RNG per partitions val r = new Random() itr.filter(x => r.nextInt(10) == 0)} Spark通过下面两种变量来实现share。
Broadcast Variables(immutable)
通常情况下,变量写在函数里就可以,但如果把一个大的lookup表或机器学习模型写到函数里,就会很低效。因每执行一个函数都要重复把变量序列化后传给需要的tasks(一个task一份)。
预先广播这些大变量,让每个executor共享。可序列化的变量才能成为广播变量。
val supplementalData = Map("Spark" -> 1000, "Definitive" -> 200, "Big" -> -300, "Simple" -> 100)val bc1 = spark.sparkContext.broadcast(supplementalData)//Java里改为final//bc1.value提取值,写在可序列化的函数里words.map(word => (word, bc1.value.getOrElse(word, 0))) .sortBy(wordPair => wordPair._2) .collect()// 提前触发广播val simMoviesBV = spark.sparkContext.broadcast(simMoviesMatrix)val abc = spark.sparkContext.makeRDD(1 to 2)abc.map(x => simMoviesBV.value.get(1)).count()//删除driver和executors的广播变量用.destroy,只删除executors用unpersist//对于不可序列化的object,用下面代码class LazyPrng { @transient lazy val r = new Random() }def customSampleBroadcast[T: ClassTag](sc: SparkContext, rdd: RDD[T]): RDD[T]= { val bcastprng = sc.broadcast(new LazyPrng()) rdd.filter(x => bcastprng.value.r.nextInt(10) == 0)} 广播后的数据被caching为Java对象在每个executor,不需要反序列化给每个task,而且这些数据可跨多jobs,stages和tasks
Accumulators(只写)
储存在driver可变的共享变量。用于debugging和聚合,但不适合收集大量数据。
在actions中,重复任务不会继续更新累加器;在transformation中,每个任务的更新可能不止一次,如果tasks stages被重新执行,而且由于lazy evaluation,不是每个transformation都能保证更新。
命名累加器便于在UI查看
caching和累加器一起运用时,即便小数据计算正确,也难保大数据正确。不过本身如果出现重复计算,累计器也不安全?
//创建命名累加器val acc = new LongAccumulatorspark.sparkContext.register(acc, "A")spark.sparkContext.parallelize(1 to 10).foreach(e => ac1.add(1))ac1.value//10 //自定义累加器class EvenAccumulator extends AccumulatorV2[BigInt, BigInt] { var num:BigInt = 0 def reset(): Unit = { //重置 this.num = 0 } def add(intValue: BigInt): Unit = { //偶数才加 if (intValue % 2 == 0) { this.num += intValue } } def merge(other: AccumulatorV2[BigInt,BigInt]): Unit = {//累加器的结合 this.num += other.value } def value():BigInt = { this.num } def copy(): AccumulatorV2[BigInt,BigInt] = { new EvenAccumulator } def isZero():Boolean = { this.num == 0 }} 广播变量只能写在driver,然后让executors读取;累加器相反,只能写在executors,让driver读取。
Part IV. Production Applications
Spark在集群上运行
紧接着Overview中的基本框架进行扩展。
Cluster Manager:在standalone模式中即为Master主节点,控制整个集群,监控worker。
Worker Node:负责控制计算节点,启动Executor Driver: 运行Application 的main()函数(向Manager申请资源和启动executor后,发送task到Executor) Executor:某个Application在Worker Node上的进程实际上,Manager是在资源协调者,如Yarn中的称呼。在Spark中将这些Manager称为Master。
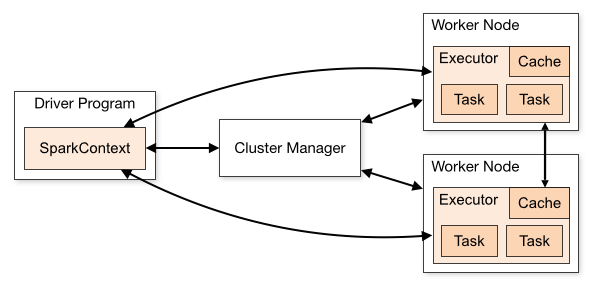
SparkContext can connect to several types of cluster managers (local,standalone,yarn,mesos), which allocate resources across applications.Once connected, Spark acquires executors on nodes in the cluster, which are processes that run computations and store data for your application. Next, it sends your application code to the executors. Finally, SparkContext sends tasks to the executors to run.
- Each application gets its own executor processes, which stay up for the duration of the whole application and run tasks in multiple threads. isolating applications data cannot be shared without writing it to an external storage system
- the driver program must be network addressable from the worker nodes. TaskScheduler会根据资源剩余情况分配相应的Task。
- DAGScheduler: 根据Job构建基于Stage的DAG(Directed Acyclic Graph有向无环图),并提交Stage给TaskScheduler。
1.模式
部署模式
cluster模式:最常用,用户在该模式下提交预编译JAR。然后manager会在一个worker节点启动driver进程,其他worker(同一个也有可能)节点启动executor进程。这意味着manager负责维护所有的Spark app相关进程。
client模式:几乎同上,但spark driver会留在提交app的机器,意味client机器负spark driver,而manager只负责executor进程。这样的client机器被称为“gateway machines or edge nodes”
local模式:整个Spark app都在一台机器上,学习和试验用。
集群运行时,尽量减少driver和Executors的距离,如用cluster模式,或driver在worker节点的client模式
集群模式
standalone中由standalone master进程和workers进程组成,只能跑spark任务
yarn中由ResourceManager进程和NodeManager进程组成
2.The Life Cycle of Application(外层)
submit jar -> 启动driver -> driver向manager申请资源 -> manager启动executor -> driver发送jar到executors,并分配task给executors让其执行jar中的某些代码
用户请求
提交任务,向manager申请,manager允许后把Spark driver放到一个worker节点上,submit结束。
/bin/spark-submit \ --class\ --master \ --deploy-mode cluster \ --conf = \ ... # other options,如Executor的数量和配置等,书中有表 \ [application-arguments]
启动Spark集群
预编译的JAR中所包含的SparkSession初始化Spark driver,包括DAGScheduler和TaskScheduler。后者的后台进程连接Manager,并注册Application,要求在集群启动Spark executor进程。manager利用资源调度算法启动executor进程(分静态和动态,独立JVM),并把进程的地址发送给Spark driver。
在Yarn模式下,submit向Yarn的resourceManager发送请求。后者分配container,根据设定的模式,yarn-cluster或yarn-client在某个nodeManager上启动applicationMaster(Driver)或ExecutorLanucher(非Driver),此时接上上面的SparkContext的初始化,但yarn-client中,executors向本地Driver注册,而不是向启动ExecutorLanucher的nodeManager。
yarn-cluster和yarn-client,前者用于生产,每个spark app在不同的nodeManager上启动Driver,不会像yarn-client那样都在本地机器,使得流量激增。但后者方便调试,log都返回到本地。
执行
DAGScheduler对app进行规划,每个action创建一个job,每个job多个stage,每个stage多个taskSet,后者的每个单位(即每个task)被TaskScheduler分到相应的executor上。
Executors有一个进程池,每收到一个task,都会用TaskRunner来封装task,然后从线程池里取出一个线程来执行task。
TaskRunner将代码复制和反序列化然后再执行task。后者分为ShuffleMapTask和ResultTask。ResultTask是最后一个stage,其他stages都是ShuffleMapTask。
executors的一个task针对一个partition执行操作,完成一个stage到第二个......期间,executors还会向driver返回结果和自身运行情况
完成
不管成功与否,Spark driver都会退出,manager关闭executors。此时用户可咨询manager结果
3.The Life Cycle of Application(内层)
每个app都是由一个或多个Spark jobs构成。Jobs是串行化执行的(除非并行启动action)。
SparkSession
把旧的new SparkContext / SQLContext模式改掉。新的方法更安全(避免context冲突)
val spark = SparkSession.builder().appName("Name") .config("spark.sql.warehouse.dir", "/user/hive/warehouse") .getOrCreate()//如果已经存在,会忽略前面的配置 SparkContext
它代表与Spark集群的连接,使用底层APIs。通常不需要显式实例化它(通过SparkSession调用)。如果创建,用val sc = SparkContext.getOrCreate()
在过去版本,通过SQLContext and HiveContext(储存为sqlContext之类的)对DF和Spark SQL进行操作,且HiveContext有更完整的SQL parser,故在没有SparkSession的版本中,更推荐。
在2.X,只要spark.enableHiveSupport()就可以对DF使用HiveQL操作。Spark可对Hive的表格进行SQL查询,并输出让其他软件使用(如Hive本身)
代码physical execution
job:由stages组成。通常来说,一个job一个action。job分解为一系列stages,后者数量取决于shuffle次数。默认FIFO,但也可以设置fair scheduler。
Stage:由一组tasks组成,Spark会将尽可能多的transformation留在相同的stage,但shuffle后(ShuffleDependencies)开始新stage。shuffle是数据的repartition,也会把数据写到磁盘。
tasks:一个task由一partition数据(按输出算)和一系列非shuffle的transformation组成,且只能运行在一个executor上。
//下面一共一个job,collect是唯一的action,6个stages,28个tasks//预先设置SQLpartition数,默认200。通常设置至少比executor数多spark.conf.set("spark.sql.shuffle.partitions", 8)val df1 = spark.range(2, 10000000, 2)//local[*]模式下,有多少个线程就多少个tasks,且range分布数据,要shuffle。此处归为Stage 0或1val df2 = spark.range(2, 10000000, 4)//Stage 0或1val step1 = df1.repartition(5)//5partition,5task,重partition要shuffle。Stage2或3val step22 = df2.repartition(6)//6partition,6task,Stage2或3val step222 = step22.filter(_ % 2 ==0)val step2222 = step2222.filter(_ % 3 ==0)val step11 = step1.selectExpr("id * 5 as id")val step3 = step11.join(step2222, "id")//shuffle,8tasks。Stage4val step4 = step3.selectExpr("sum(id)")step4.collect()//包含action的计划在UI看。shuffle,1task,Stage5 一般stages是按顺序的,但上述两个RDD的stage可以并行(不同rdd+join)。即便如此,一有宽依赖计算就要按顺序来。
shuffle慢的原因:数据移动,潜在的I/O,限制并行(完成shuffle才能下一步)
执行细节
pipeline过程在一个node中完成,且不会写到内存或磁盘。
Spark总是让发送数据的任务在执行阶段,把shuffle文件写入磁盘。这有利于后续计算(如果没有足够executors同时执行计算,就先执行I/O再计算)和容错(不需要重新shuffle数据)。
Spark App开发
App由集群和代码构成
object DataFrameExample extends Serializable {//序列化 def main(args: Array[String]) = { if (args.length != 2) { println("Usage: logCleanYarn ") System.exit(1) } val Array(inputPath, outputPath) = args val spark = SparkSession.builder().appName("Example") .config("spark.sql.warehouse.dir", "/user/hive/warehouse") .getOrCreate()//appName,config等在生产环境中,去掉,在submit时设定。 val df = spark.read.json(inputPath) df.write.format("parquet").partitionBy("day").save(outputPath) }} 利用maven进行编译mvn clean package -DskipTests,当要将不同路径的jar都打包到一个jar包中时,在pom.xml中配置maven-assembly-plugin,然后mvn assembly:assembly
用scp .jar hadoop@hadoop001:~/lib/传到hadoop的master上。如果项目的resource中有文件,则需要另外scp到远程。
一般把下面的代码写到脚本中,以yarn为例
export YARN_CONF_DIR=path/of/hadoop #也可以在spark的conf文件设置$SPARK_HOME/bin/spark-submit \ --class com.databricks.example.DataFrameExample \ #写到类名,在idea中直接右键类名copy reference --name xxx\ #生产环境加上 --master yarn \ #或yarn-cluster --conf spark.xxx.ss.xx=xx --files path/file1, path/file2 \ #额外用到的resource中的文件,此处为上面传到hadoop中的位置 --jars xxx.jar \ #有额外jar时,比如用Hive时,加上mysql-connector-java的jar包 #其他还有--num-executors/ --driver-memory/ --executor-cores --conf 等 path/xxx.jar \ #jar的位置,一般为上面传到hadoop中的位置 path/xxx.json #数据源位置,即上面的inputPath path #输出位置
分开启动master和workers
start-master.shstart-slave.sh#配置-h #在哪里启动,默认本机。也可以在spark-submit、spark-shell、代码中设置-p #启动后使用哪个端口对外提供服务,master默认7077,workers随机--webui-port #UI端口,master默认8080,worker 80801-c #worker的core数量,默认当前机器所有cores-m #worker的内存,默认1g-d #worker工作目录,默认SPARK_HOME/work
App其他相关
开发策略
- 顾及边缘类型数据。
- 从真实的数据中做逻辑测试,保证你写的代码不是仅仅符合Spark功能,还要是符合业务的。
- 输出结构,确保下游用户理解数据的情况(更新频率,是否已完成等)
测试:JUnit or Scala Test
开发流程:一个临时空间,如交互式notebook。当完成一个关键部分,保存为库或者包。
配置App
SparkConf:
val conf = new SparkConf().setMaster("local[2]").setAppName("DefinitiveGuide")//在UI中的名字 .set("some.conf", "to.some.value")” 也可以在spark-submit中配置
硬编码配置:如通过conf/spark-env.sh设置环境变量(IP地址等),log4j.properties配置登录
其他可配置的还有运行时属性、执行属性、内存管理(和终端用户关系不大,2.X自动管理)、shuffle行为、环境变量、job Scheduling
Monitoring and Debugging
Spark UI和Spark logs,JVM,OS,Cluster
监测:processes(CPU、内存等)和query execution(jobs和tasks)
UI
Jobs
看整体,选择耗时的stage进一步分析。
Stage
DAG看整个stage的规划,可以了解哪段代码比较耗时
Event Timeline看各个核的再各时间段都在做什么,比如shuffle、计算、任务序列化、规划等。
Summary Metrics 看最大值和平均值的差距,如用时、GC、shuffle等,判断是否数据倾斜
Shuffle Spill(Memory)和Shuffle Spill(Disk)分别代表在实现Shuffle时中写入内存和硬盘的数据量,对调优帮助不大。
Tasks看Attempt和Locality Level
shuffle write - Data move from Executor(s) to another Executor(s) - is used when data needs to move between executors (e.g. due to JOIN, groupBy, etc)
An edge case example which might help clearing this issue:
- You have 10 executors
- Each executor with 100GB RAM
- Data size is 1280MB, and is partitioned into 10 partitions
- Each executor holds 128MB of data.
Assuming that the data holds one key, Performing groupByKey, will bring all the data into one partition. Shuffle size will be 9*128MB (9 executors will transfer their data into the last executor), and there won't be any spill to disk as the executor has 100GB of RAM and only 1GB of dat
部分参考:https://stackoverflow.com/questions/41661849/spill-to-disk-and-shuffle-write-spark
常见问题
启动、执行前、执行中。
Driver OutOfMemoryError or Driver Unresponsive:用了collect,broadcast数据太大,长时间运行APP产生大量数据,JVM的jmap
Executor OutOfMemoryError or Executor Unresponsive:少用UDF,JVM的jmap
Unexpected Nulls in Results:利用累加器计算raw data是否转化成功
磁盘空间:设置log配置(logs保持的时间)
其他包括:序列化出错,unexpected null
Unit test
常规的Spark:分为单个函数和整个流程(即所有函数组合起来)。前者看如何分解函数,后者可参考《high performance spark》的模版,编写输入和期望输出,然后在本地比较期望输出和实际输出。如果结果太大,可用toLocalIterator。
Streaming:输入用file(maxFilesPerTrigger)或socket来模拟数据源,输出用console或memory sink
DF:测试collect后的List(Row(...))。如果是ByteArrays,则要比较值。对于浮点结果,可用“assertDataFrameApproximateEquals(expectedDf, resultDF, 1E-5)”或者“assert(r1.getDouble(1) === (r2.getDouble(1) +- 0.001))”,查看spark-testing-base的equalDataFrames和approxEqualDataFrames
RDD:(order matters or not):如果两个RDD经过sortByKey(partitioner相同时),可以zip两个rdd后直接比较,否则其中一个需要repartition后再比较。详细《high performance spark》中的代码。
测试数据
自编:纯手动,RandomRDDs,RandomDataGenerator
def generateGoldilocks(sc: SparkContext, rows: Long, numCols: Int): RDD[RawPanda] = { val zipRDD = RandomRDDs.exponentialRDD(sc, mean = 1000, size = rows) .map(_.toInt.toString) val valuesRDD = RandomRDDs.normalVectorRDD( sc, numRows = rows, numCols = numCols) zipRDD.zip(valuesRDD).map{case (z, v) => RawPanda(1, z, "giant", v(0) > 0.5, v.toArray) }} sample:
常规抽样:sample根据是否能replacement会创造poisson 或 bernoulli的PartitionwiseSampledRDD,也可以自定义sampler,例如为了sample一份样本和一份inverse样本。
分层抽样:sampleByKeyExact 和 sampleByKey的fraction用Map来确定各key的比率(占原数据的)
抽取多份样本:randomSplit
DF不支持分层抽样
Property Checking
sscheck和spark-testing-base。可以设定outputs类型,让testing library自动生成test input。
参考:
书籍:Spark: The Definitive GuideHigh Performance Spark